Improving Lucee's Query of Query Support
One of the really great features of CFML is the ability to run SQL against a result set in memory. This allows you to union separate results together or even apply additional filtering on an exiting result if you can't control what the DB gives you. Like everything, there is a time and a place for this. There are people who strongly dislike QoQ (query of queries) but my take is that I think they're great when used with relatively small data sets and unless performance profiling shows they are causing issues, I have no problems using them.
The Lucee developers however have often told people never to use QoQ because they were slow. Recently, I found out why. Ortus has a client moving a large application over from various versions of Adobe ColdFusion to Lucee Server. They have a lot of reports that grab a query from the DB and then chop it up inside loops using QoQ to crunch the data and generate the output. This has worked well for them in Adobe CF for years, but when testing their site in Lucee, the pages slowed to a crawl. And then more than one user hit their site at once, it got even worse! This client asked Ortus/me to take a look at help them figure out why Lucee was so slow.
Three QoQ Implementations
I received a standalone test file that ran around 1,000 QoQ's in it and I fired up the FusionReactor Profiler to see what was going on. I really can't understate the amount of time saved with FusionReactor here. I have used it in every step of this process. Lucee is also open source, so I began reviewing the implementation of QoQ to see how it worked. The first thing I found is that there are actually three implementations of QoQ in Lucee, and if one fails, Lucee just discards the error and moves on to the next one to see if it fares better.
- Native QoQ - In memory manipulation of the result set
- Another? Native QoQ - A copy of the first but... different. I'm unclear why this one exists or in what ways it's different. I think it may have been an experiment at one point that was never removed.
- HSQLDB via JDBC - A Java-based disk/memory DB called HyperSQL that is accessed via JDBC
Poor Native QoQ Support
The first two native implementations are very limited. They
- Don't support group by clauses
- Don't support having clauses
- Don't support aggregate functions
- Have bugs in their UNION functionality
- Have bugs in their DISTINCT function when used with maxrows
- Have bugs in their parser that throws errors on valid SQL
- Have slow performance. Results are sorted up to 3 times in some cases, the distinct function is slow, and the code is not tuned well
HSQLDB Fallback
So basically, any SQL of medium complexity past a simple select will hit the native implementation and error out. Lucee will catch this error and simply move on to the HSQLDB implementation. These errors happen every single time as well. Lucee isn't smart enough to remember when a query requires HyperSQL.
Running the Select in HSQLDB looks like this:
- An on-the-fly JDBC datasource connection to an internal HSQLDB is created
- A table is created in the DB and loaded with your data
- The SQL is passed via JDBC to HSQLDB for execution
- The result is returned
- Since there is only a single HSQLDB created behind the scenes, this entire process is SINGLE THREADED to prevent more than one QoQ hitting it at a time.
The four main issues here are:
- The single threaded nature just kills performance under load. Only a single QoQ can run at one time for an entire server. This is a non-starter and explains why my client's site just crumbled under the load of a few users for these QoQ-heavy pages that ran fine in Adobe CF
- The overhead of a JDBC call can be around 20 ms per call. This may seem small, but you run 1,000 QoQ's in a page and suddenly you have 20+ seconds of nothing but JDBC overhead. FR's query tracing can actually dog pile on this to make it even worse.
- The HSQLDB engine isn't great and Lucee has no direct control over it to add features and fix bugs
- Since Lucee discards the errors from the native implementation, there is NO WAY to know when your query has "fallen back" to the HSQLDB implementation other than looking in FusionReactor's JDBC tab to see if the QoQ's were tracked as JDBC calls.
The Fix
I was able to initially "tip toe" around the issues above by rewriting all their QoQ's to avoid the HSQLDB fallback and implement their aggregate functionality in CFML directly. This worked pretty well and query objects have a lot of really great member functions nowadays which I recommend looking into. However, my client's investment in QoQ involves a LOT of code and there is really no reason why they shouldn't be able to continue using the same code that's run great on Adobe CF for many years. As such, we discussed and decided to sink some effort into Fixing Lucee's native QoQ support so it could support the features they needed and at a much faster performance level without the need to rewrite all their code.
This body of work has culminated in this Lucee ticket:
https://luceeserver.atlassian.net/browse/LDEV-3042
And this pull request:
https://github.com/lucee/Lucee/pull/1026
Update 9/21/2020 - This pull has been merged into the 5.3.8.74 snapshot!
I have completely re-worked the native QoQ implementation in Lucee with the following fixes and improvements:
- group by clause support
- having clause support
- aggregate function support
- Allow aggregates to reference nested operations including scalar functions
ceiling( max( floor( yearsEmployed ) )+count(1) )
- Faster distinct support
- Fix buginess in unions were results aren't distinct by default (union distinct)
- Improve count() to support
count( all col )count( 1 )count( * )count( 'literal' )count( distinct col )count( distinct scalarFunc( col ) )
- Fix bugs in SQL parser that incorrectly requires only a single space between multi-word clauses
is nullis not nullnot innot likeorder bygroup by
- Remove single-threaded limitations
- Performance tune speed of queries
I have also added support for the following system props/env vars
- lucee.qoq.hsqldb.disable=true – Throw exception if native QoQ logic fails
- lucee.qoq.hsqldb.debug=true – Log message to WEB context's datasource log any time a QoQ "falls back" to HyperSQL. This could include just bad SQL syntax.
The long and short of this should be that your QoQ's run the same they always have. But now they should be much faster since they no longer fall back to HSQLDB for most operations. The one exception right now is performing joins against more than one query object. I'd love to help add support for this, but my client didn't need it and it was a significant amount of additional work. QoQ's with joins will continue to fall back to HSQLDB for now.
Test Coverage
Every inch of the new implementation has been commented in the code to explain what it's doing and I have added dozens of new tests to the Lucee test suite to cover all of this functionality. The new test suite can be found in my pull request above.
Performance Gains
Here's the icing on the cake. I performed a battery of tests against
- Lucee 5.3.6 (stable)
- Lucee 5.3.6 (with new LDEV-3042 fixes)
- Adobe ColdFusion 2018 update 10
The test data was a 30,000 row in-memory query object. Each test was run 100 times sync and 100 times async. Total numbers are reported in milliseconds and represent the summed execution times of all 100 runs. Async runs used a pool of 20 threads to simulate concurrent traffic.
The new Lucee QoQ implementation is faster in every single test and it's faster than Adobe ColdFusion in 6 of the 8 tests. in fact, the more complex the queries get, the better the new QoQ support works. Here's a PDF of this data.
https://drive.google.com/file/d/12iqZhbIh62spdJBQC2MaOroiMf8D4l7L/view?usp=sharing
I played a lot with adjusting the size of the query object being selected against and the number of iterations. I found that both variables result in a linear increase in query time, thus fairly irrelevant. I settled on 30,000 rows as a nice large number that pushes the limits of the amount of data someone is likely to have in memory. The 100 iterations just just a good solid number of times to ensure the total result time was large enough to compare with accuracy. The execution of a single query is roughly 1/100th of the total time shown in each box.
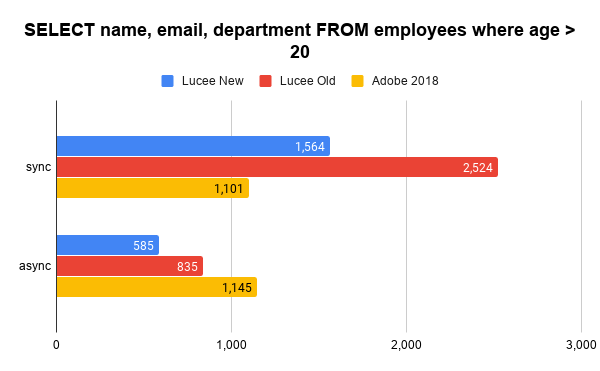
Note, this SQL was simple enough it didn't "fall back" to HSQLBD which is why the async test is better for the old Lucee.
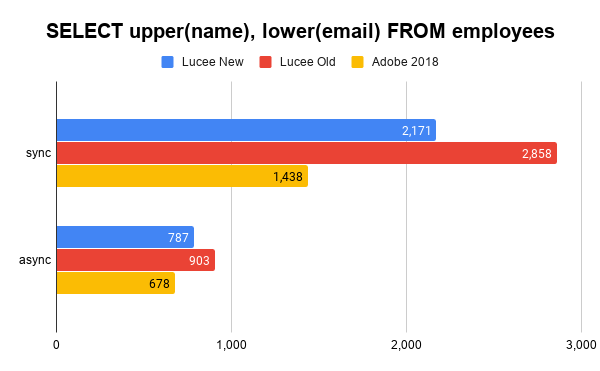
Note, this SQL was simple enough it didn't "fall back" to HSQLBD which is why the async test is better for the old Lucee.
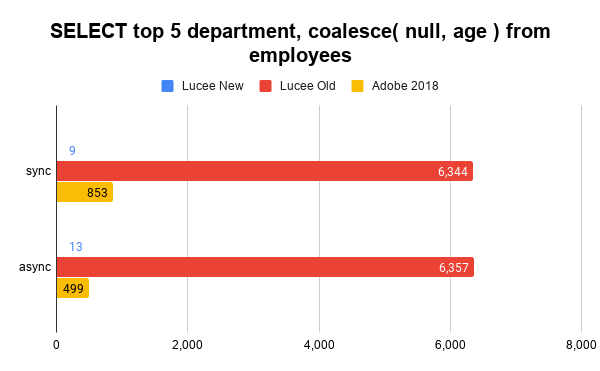
Note, Here we see old Lucee falling back to HSQLDB finally which is why the async times aren't any better due to the singlet threading. Adobe CF does not support "top" so I used "maxrows" instead. Adobe CF also doesn't support coalesce(), so I removed it for the Adobe test.
The new implementation is so much faster because this select can be optimized with an "early return" after the first 5 rows are processed since there is no grouping or ordering required. I made sure to optimize for these scenarios, when possible.
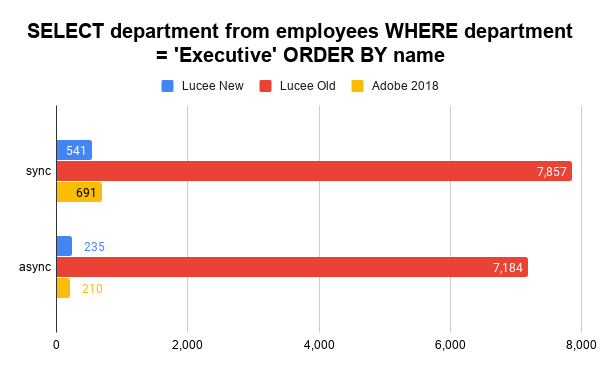
Note: Luce old falls back to HSQLDB here.
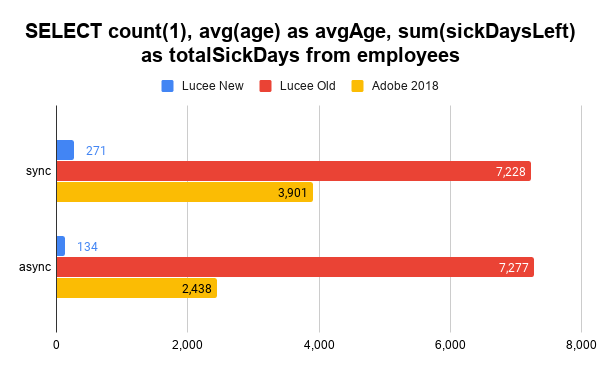
Note: Luce old falls back to HSQLDB here. The new Lucee implementation's fast partitioning for the aggregates really starts to shine here over Adobe.
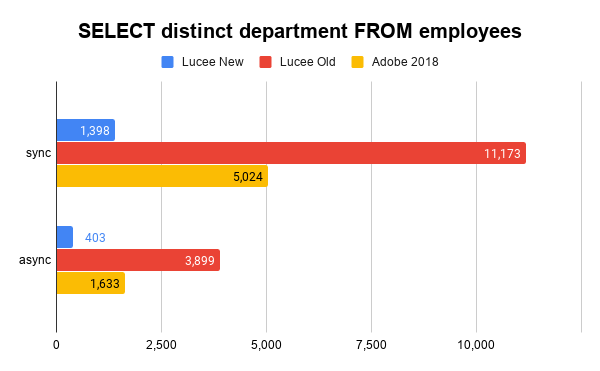
Note: Luce old does not fall back to HSQLDB here, but is still much slower due to using a less efficient algorithm for distincting.
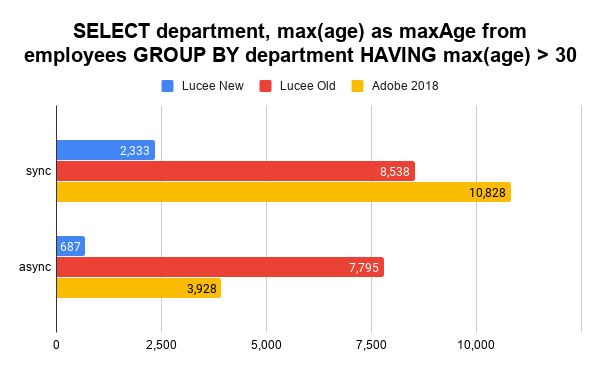
Note: Luce old falls back to HSQLDB here.
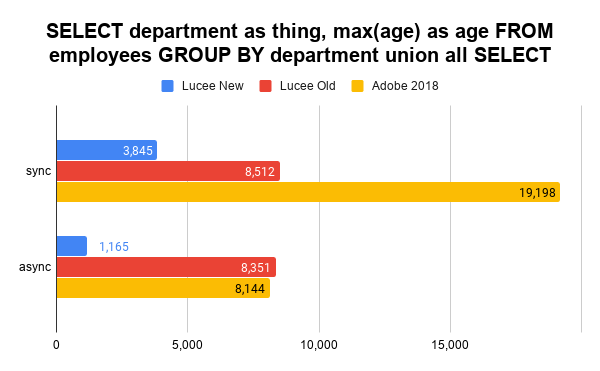
Note: Luce old falls back to HSQLDB here.
Final Thoughts
Hopefully this pull request is reviewed and merged into the Lucee core. These changes were sponsored by UNOSOF but they will benifit much more than my client. Lucee 5.3.7 is already in release candidate form, so I've sent the pull request to the 5.3 branch which is where the 5.3.8-snapshot currently lives. Feel free to chime in on the ticket or pull to "encourage" the Lucee team in reviewing this! If you would like to help test this, you can grab one of the following Lucee core files:
- https://downloads.ortussolutions.com/lucee/lucee/5.3.6.66-QoQ/5.3.6.66-QoQ.lco - For a 5.3.6 stable installation
- https://downloads.ortussolutions.com/lucee/lucee/5.3.6.66-QoQ/5.3.8.77-QoQ.lco - For the current bleeding edge 5.3.8-snapshot release
Files last updated 10/06/2020
Drop the lco file into your server context's /deploy folder and wait up to 60 seconds, or drop it in your /patches folder and restart. If you're using CommandBox, click your tray icon and select "Open..." > "Server Home" to find these folders. They are under WEB-INF/lucee-server/
Test with one or both of the ENV args defined above enabled so you can see the actual errors if the native QoQ fails. Otherwise the HSQLDB "fall back" will cover up the real errors. In CommandBox, you can enable the new flags like so:
server set JVM.Args='-Dlucee.qoq.hsqldb.disable=true' or... server set JVM.Args='-Dlucee.qoq.hsqldb.debug=true'
Please report any issues to me with a test case and the full stack trace.
Also, big thanks to Scott Steinbeck and Zac Spitzer for helping me test this so far.