Improving Lucee's QoQ Support Again- now 200% faster
Update 1/27/2023 - the pull has now been merged into the snapshot builds of Lucee 6!
Two years ago, I published this post detailing how I had refactored the Query of Query support in Lucee to be much better and also much faster:
https://www.codersrevolution.com/blog/improving-lucees-query-of-query-support
I removed the single-threaded HSQLDB callback for grouped/aggregate and distinct selects and tuned the performance. QoQ's are a bit of a polarizing feature in CFML. They've suffered in the past from poor support and poor performance which has caused a lot of people to avoid them. There are certainly places where queryMap(), queryFilter(), and queryReduce() are the best approach, but there are also times where you simply can't beat the readability and conciseness of an ordered, aggregated select. I know developers who tell me they never use "reduce" higher order functions because they are too confusing, but I've never met a developer who didn't understand "GROUP BY department"!
I've got several other ideas to increase the feature set of QoQ in CFML including native support for INNER and OUTER joins as well as this idea of exposing CFML string, number, and date functions directly in QoQ. I've also put in a handful of tickets for Adobe ColdFusion to invite them to follow in the improvements I've added to Lucee. I'd send them pulls, if I could : (
The Improvement
OK, so let's get into it. This improvement was something I wanted to play with ever since my first foray into Lucee's QoQ code, and that was to use Java's parallel streams to improve the performance. Basically when you process a large query object, the rows are looped over sequentially, which only really uses a single CPU core for the loop. Java Streams are a feature that came out in Java 8 (see cbstreams for the CFML wrapper) and one of their most amazing features is the ability to easily mark a stream as parallel, which will use a pool of threads to process the items. Java Streams use the JDK's default fork/join pool which has as many threads as you have CPU cores. This is perfect for CPU-bound operations and also means the more cores your server has, the better performance gains you'll see!
Most of the logic that runs for a Query of Query is inside of a loop. For example:
SELECT * FROM qry WHERE col > 5 ORDER BY col
will
- Loop over the source qry to filter records matching the WHERE clause
- Loop over the matches to build up the new query object
- Loop over the final query to apply the sort to it
Partitioned queries such as DISTINCT, GROUP BY, or any select with an aggregate function have even more steps to organize the data. It only makes sense to tap into all your CPU cores to do this.
The Hurdles
Generally speaking, this change wasn't too difficult, it just required a lot of testing, and patience to put up with writing Java for a week, lol. As there is not a way to represent a query row as an individual object in Lucee's core (data is stored in columns), I used Java's IntStream class to create a stream from 1 to the recordcount to "drive" the process, where the current int in the stream represented the row number. There were several bits of logic in Lucee that were not thread safe initially. For example, when adding a row to a query, the added row number was not returned, but instead the current recordcount which, in a multi-threaded environment, may not be the specific row you just added, but instead a row another thread added! This is already a known issue when adding rows in CFML too.
I also carefully examined the locking Lucee performs under the hood to keep query objects safe. Java's oldest and simplest locking mechanism is to mark an entire method as synchronized or to use a synchronized block around some code. This is the equivalent of an exclusive CFLock in CFML and while effective and fast, is often times heavy-handed. Lucee's query objects use a native Java array in each column for performance, but one huge downside is a native Java array cannot be resized. Once it fills up and you attempt to add a new row, a new larger array must be declared, all data copied over to it, and swapped out. This is fast-ish, but requires all set operations on a query to employ a lock to ensure they don't try to set data while the internal native array is being grown. This also means only one thread can call a set() method at the same time! Java has read/write locks, but they perform so slowly under load, they are as bad a synchronized methods. I minimized the locking as best I could and entered a ticket for a future enhancement to completely re-think how Lucee stores data with a growable array of array "chunks".
The rest of the hurdles were mostly Java being the annoying, pedantic, strict language that Java is. The functional interfaces for Lambdas also do not allow any typed exceptions to be thrown which is a terrible design on Oracle's part and requires additional boilerplate to work around. Trust me CF devs, you don't know how good you have it!
A Few Details
My work for this culminated in this ticket: https://luceeserver.atlassian.net/browse/LDEV-4298
And this pull request: https://github.com/lucee/Lucee/pull/1887
Big thanks to Peter Amiri who offered to help sponsor this work. Without this I wouldn't have had the time to complete this effort.
You can read more detail there including a new setting to control the parallelism in QoQ if you want. By default, any QoQ on a query object less than 50 rows will execute sequentially (no threads) because the overhead of managing the joining the threads is normally more than the benifit. 50+ rows seems to be where the benifit outweighs the overhead, so all query objects with that least that many rows will be processed in parallel.
I also completely rewrote the ORDER BY functionality. Previous versions would sort the entire query object once for each order by column, starting from the right to the left, to leave the final query in the sort desired. This was greatly improved by not only switching to a parallel stream for sorting, but also writing a new QueryComparator class which sorts all columns at the same time, short circuiting when possible. If the first column's data sorts higher or lower than the other row, there's no need to keep comparing. The new single-pass QueryComparator provided up to 3x faster speed, and when you add in the parallel streams, large ORDER BY clauses are now up to 5x faster!
It's also worth noting that the outward behavior of QoQ should go untouched with one small caveat. Previously, if you didn't use an ORDER BY clause in your QoQ, the records for a simple select would tend to say in their original order due to the implicit encounter order of a standard loop. With parallel streams, you can't know which threads will complete first, so the rows may be in an order you don't expect. This, of course, is by-design and the appropriate fix is to use an ORDER BY if the order of the final results is important to you.
The Results
Ok, time for the good stuff. The asynchronous improvements had a huge affect. I put "200%" in the blog post title and I'm well aware of the ambiguity of that statement, lol. The results vary, but generally speaking, any QoQ of relative complexity completes in less than half the original time, giving you a throughput of more than twice the original. So whether you want to call that a 50%, 100% or 200% improvement is up to you :)
I found the improvement in performance to be fairly stable regardless of the number of rows in the source query. The larger determining factor of improvement was actually the complexity of the query. So the number of selects, number of group bys, size of the where, number of order bys, etc has the most affect. The more your queries do, the faster they will get. The last time I did this, I used a source query with 30K rows and 100 passes. I really wanted to push the limits this time, so I tested a single pass on a 1 Million row query. I was pleasantly surprised with how Lucee handles 1 million rows in a QoQ in stride! I wanted to compare to Adobe CF again, however I was NOT impressed with Adobe's performance. Once you get over 200K - 300K rows, the wheels start to fall off Adobe's QoQ. Therefore, I did not include Adobe in the comparisons because they couldn't take the preverbal heat in the kitchen. I have one graph that shows Adobe and Lucee side by side across a varying range of query sizes up to 1 Million.
- Where the graphs say Lucee 5, that is Lucee 5.3.10+97
- Where the graphs say Lucee 6, that is the bleeding edge of Lucee 6.0.0.300-SNAPSHOT WITH MY NEW CHANGES that are present in the pull request above.
- Where the graph says Adobe, that is Adobe ColdFusion 2021.0.05.330109
Each set of numbers represents the milliseconds to complete the query, so a lower number is better because it was faster. I ran each test at least once to ensure everything was compiled and warmed up.
Query 1
SELECT name, age, ucase( email ) as email, department, isContract, yearsEmployed, sickDaysLeft,
hireDate, isActive, empID, favoriteColor, yearsEmployed*12 as monthsEmployed
FROM employees
WHERE age > 20
AND department IN ('Acounting','IT','HR')
AND isActive = true
ORDER BY department, isContract, yearsEmployed desc
| Lucee 6 | Lucee 5 |
| 1,123 ms | 3,595 ms |
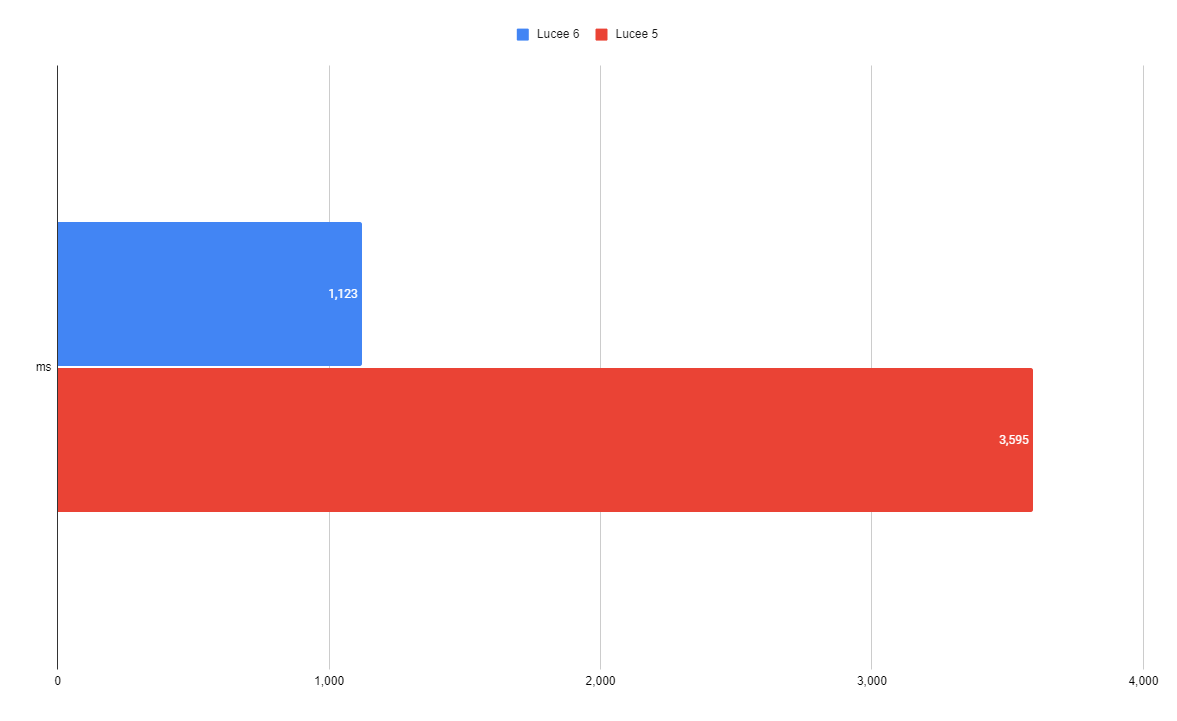
This is a basic non-grouping, non-aggregate select with a WHERE clause, a couple expressions in the SELECT list, and an ORDER BY. The new QoQ is over 3x faster than before.
Query 2
SELECT name, age, ucase( email ) as email, department, isContract, isActive, empID, favoriteColor, yearsEmployed*12 as monthsEmployed
FROM employees
where age > 20
AND department = 'HR'
AND isActive = true
UNION
SELECT name, age, ucase( email ) as email, department, isContract, isActive, empID, favoriteColor, yearsEmployed*12 as monthsEmployed
FROM employees
where age > 20
AND department = 'Acounting'
AND isActive = false
order by department, name, email, age desc
| Lucee 6 | Lucee 5 |
| 1,567 ms | 3,798 ms |
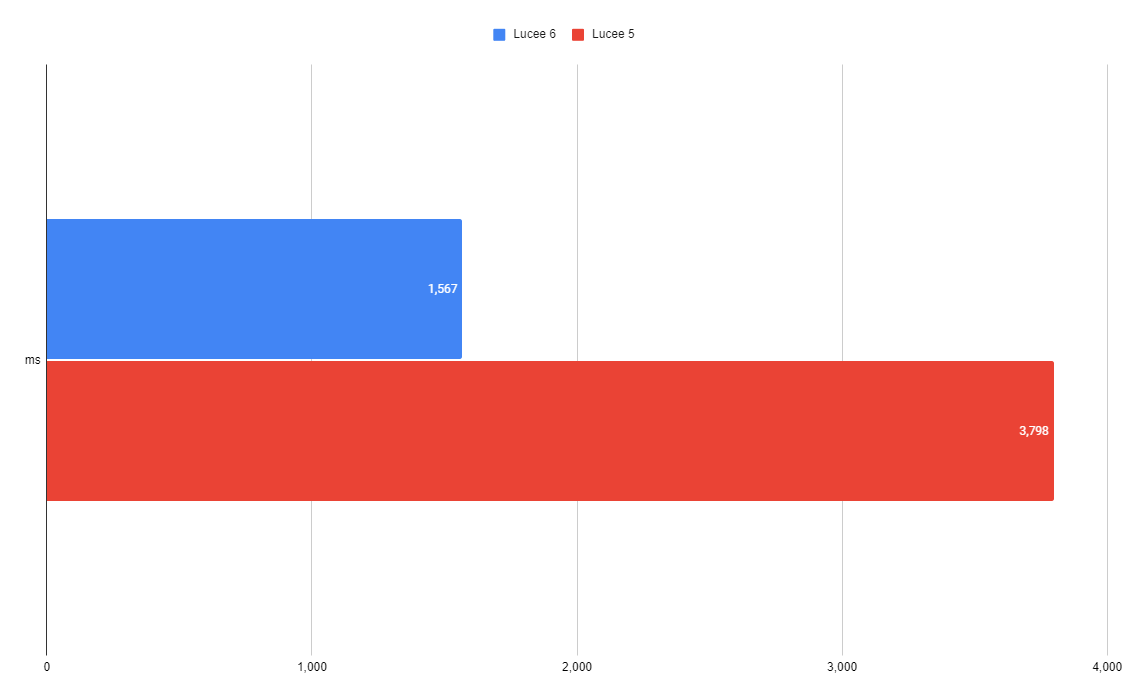
Here we have two non-grouping, non-aggregates selects UNION'ed together (DISTINCT is implied). The new QoQ is 2.4x faster than before.
Query 3
SELECT max(age) as maxAge, min(age) as minAge, count(1) as count
FROM employees
where department IN ('Acounting','IT')
AND isActive = true
| Lucee 6 | Lucee 5 |
| 683 ms | 1,159 ms |
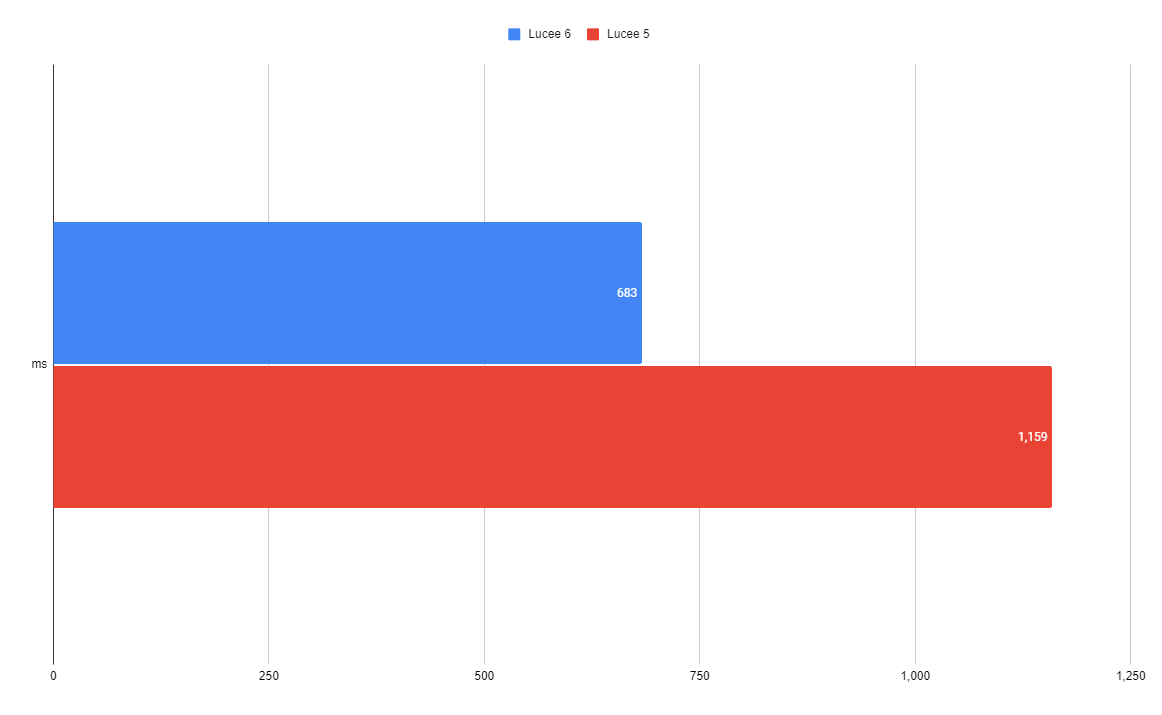
Here we have simple non-grouping, aggregate select. It only outputs one row, so it's already fairly fast. The new QoQ is 1.7x faster than before.
Query 4
SELECT age, department, isActive, isContract, count(1) as count
FROM employees
where age > 20
AND isActive = true
group by age, department, isActive, isContract
HAVING count(1) > 3
ORDER BY age, department, isActive, isContract
| Lucee 6 | Lucee 5 |
| 357 ms | 1,136 ms |
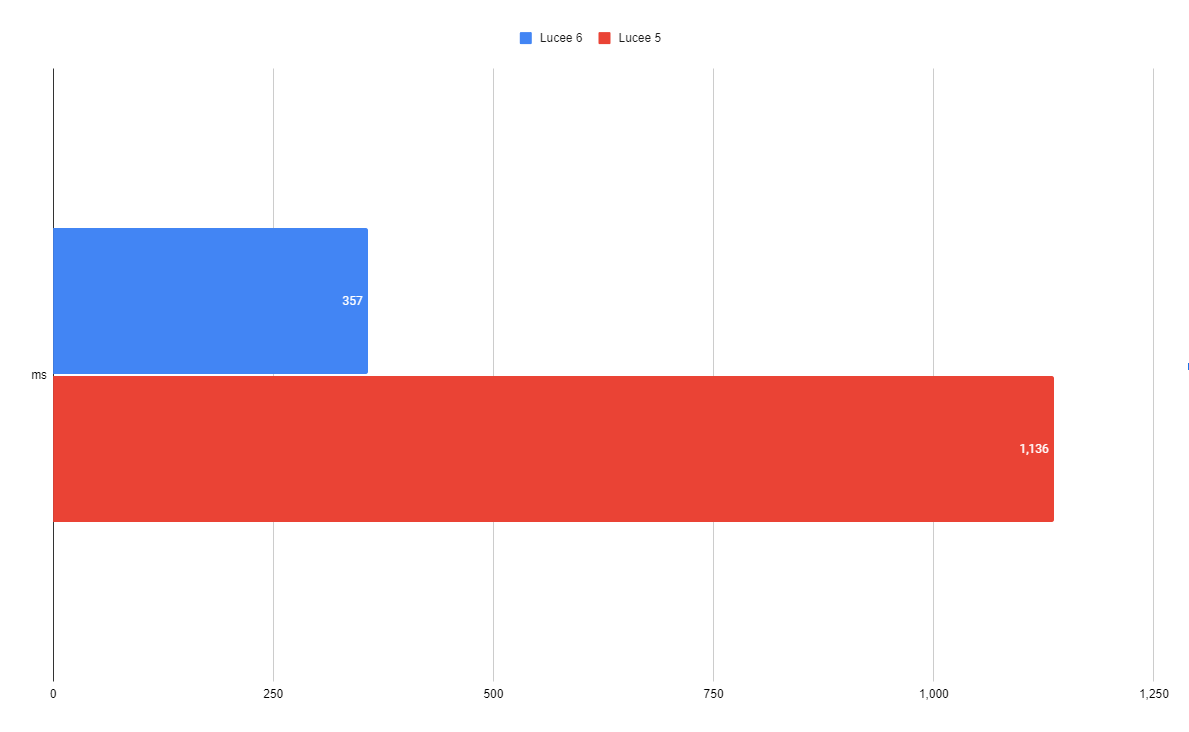
This select uses a WHERE, a GROUP BY, a HAVING, an ORDER BY and aggregate functions-- so basically everything! The new QoQ is over 3x faster than before.
The next two graphs highlight some serious performance issues that I consider bugs in Lucee 5 and Adobe CF. A small overhead can become a large overhead under enough load.
Lucee String Concat
SELECT name + age as nameAge FROM employees
| Lucee 6 | Lucee 5 |
| 252 ms | 5,953 ms |
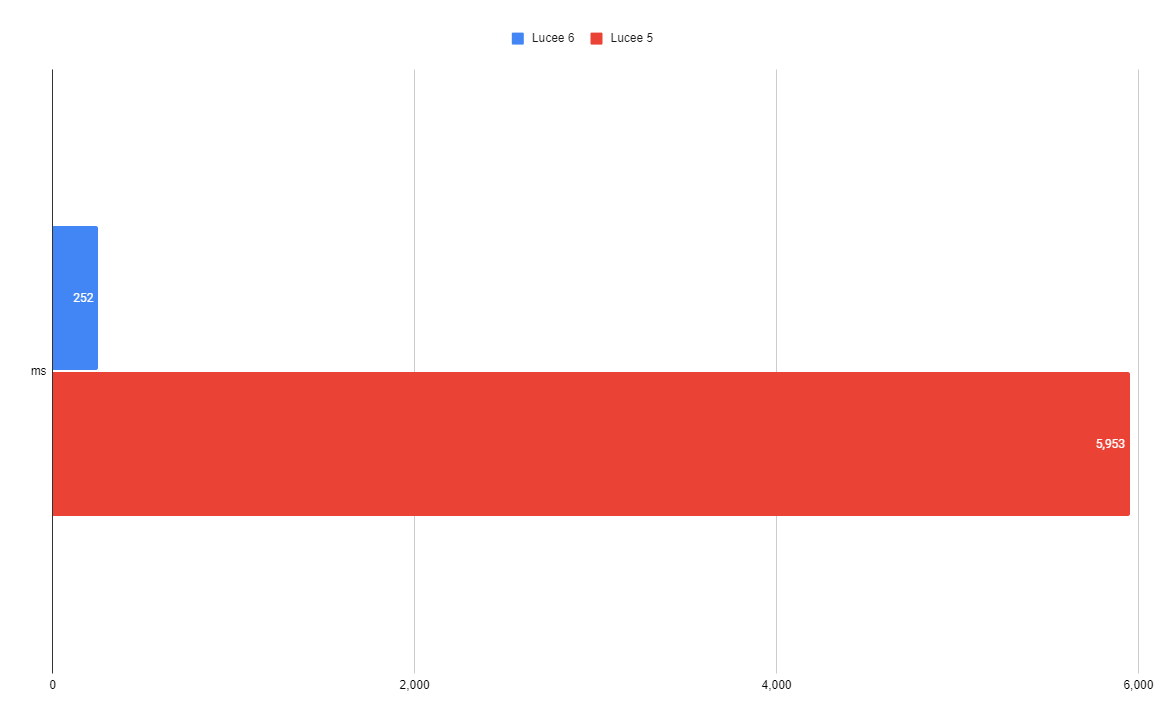
This query may look simple, but it performs terrible in Lucee 5. QoQ overloads the "+" operator to perform an arithmetic addition on two values that can be cast to numbers, but it concatenates if both values can't be cast. Previously, Lucee would attempt to cast both values to a number inside of a try/catch, and if it failed, assume they were strings. This bogs down heavily under load and I refactored the logic to use the isNumeric() check instead. Lucee is now 24x faster in this example. I avoided using the "+" operator in the other tests due to this.
Adobe LIKE operator
SELECT * FROM employees where name like '%Harry%'
| Lucee 6 | Lucee 5 | Adobe CF |
| 17 ms | 61 ms | 3,145 ms |
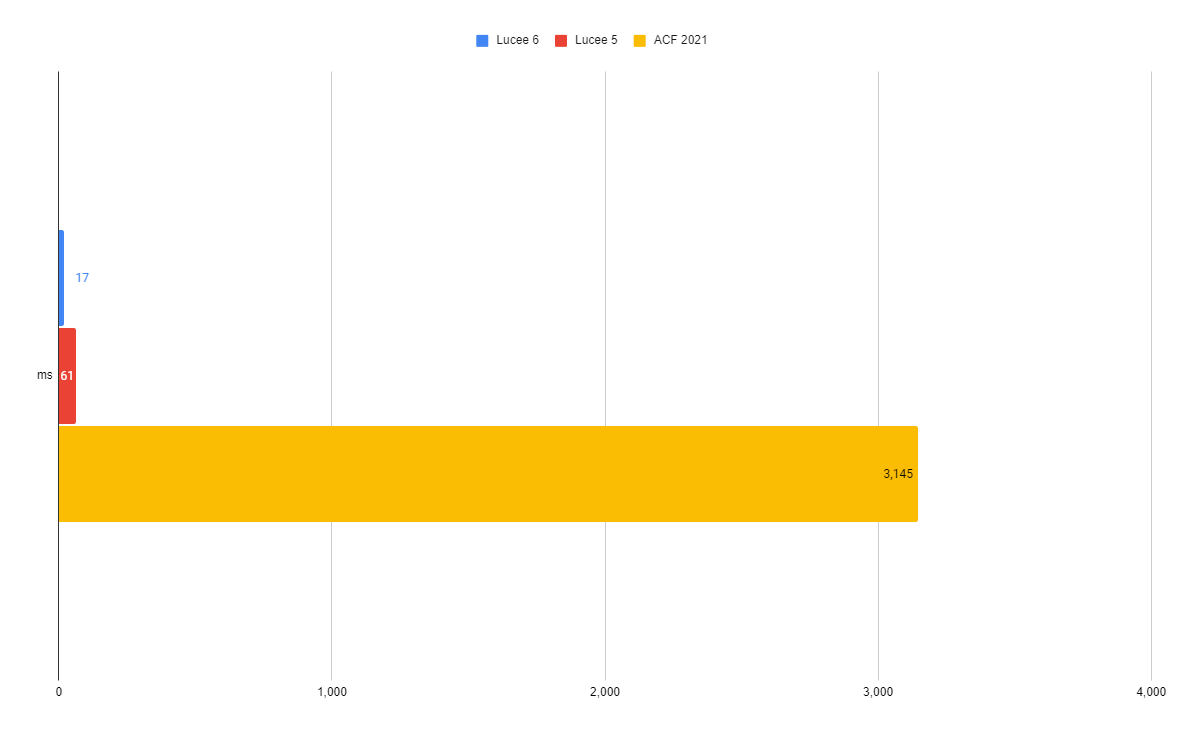
This query may also look look simple, but it performs terrible in Adobe CF. Behind the scenes, the LIKE operator is compiled to a regular expression. (Java regex gets compiled!) Lucee has always cached these compiled regex's, but from looking at stack traces, it appears Adobe CF re-compiles the regex every single time! This creates quite a slow down in Adobe QoQ's using LIKE. Lucee 5 was 51x faster than Adobe CF and Lucee 6 is 185x faster than Adobe CF in this test. I avoided using LIKE in the other tests due to this.
I also tried to put in a ticket for Adobe in their bug tracker, but it was acting up that day. I ended up having to E-mail the engineering team to enter the ticket for me and it doesn't show up anywhere so I'm not entirely sure what happened to it :/
This final test shows the relative performance of Lucee 5, Lucee 6, and Adobe CF side-by-side running the same QoQ against source queries of different size.
Lucee 5, Lucee 6, and Adobe CF side-by-side
SELECT age, department, isActive, isContract, count(1) as _count
FROM qry
where age > 20
AND isActive = 1
group by age, department, isActive, isContract
HAVING count(1) > 3
ORDER BY age, department, isActive, isContract
I'm not providing the full data here for brevity, but I'll gladly share it with anyone who is curious.
| Lucee 6 | Lucee 5 | Adobe CF |
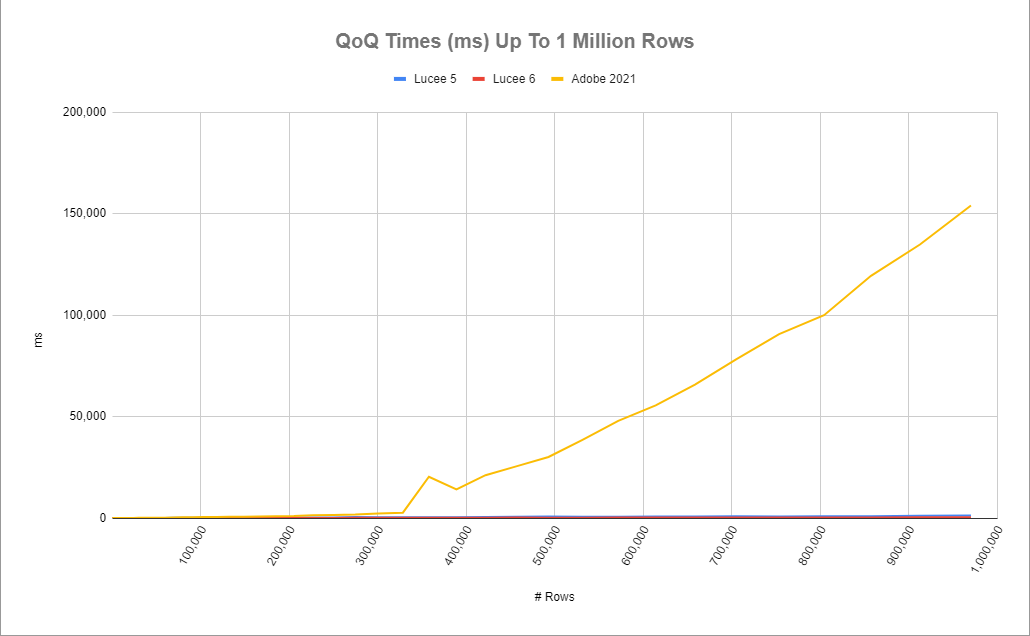
You may recognize this query from above. It's a basic grouped, ordered select. Looking at the graph, wowzas! Adobe's QoQ grinds down to a crawl once you get past 300K rows! I can see why people have historically shied away from using QoQ for larger amounts of data. But it's time to challenge those old views-- at least if you're using Lucee! Let's zoom in a bit on that graph so we can see how Lucee 5 compares to Lucee 6 across the same range of query sizes.
| Lucee 6 | Lucee 5 | Adobe CF |
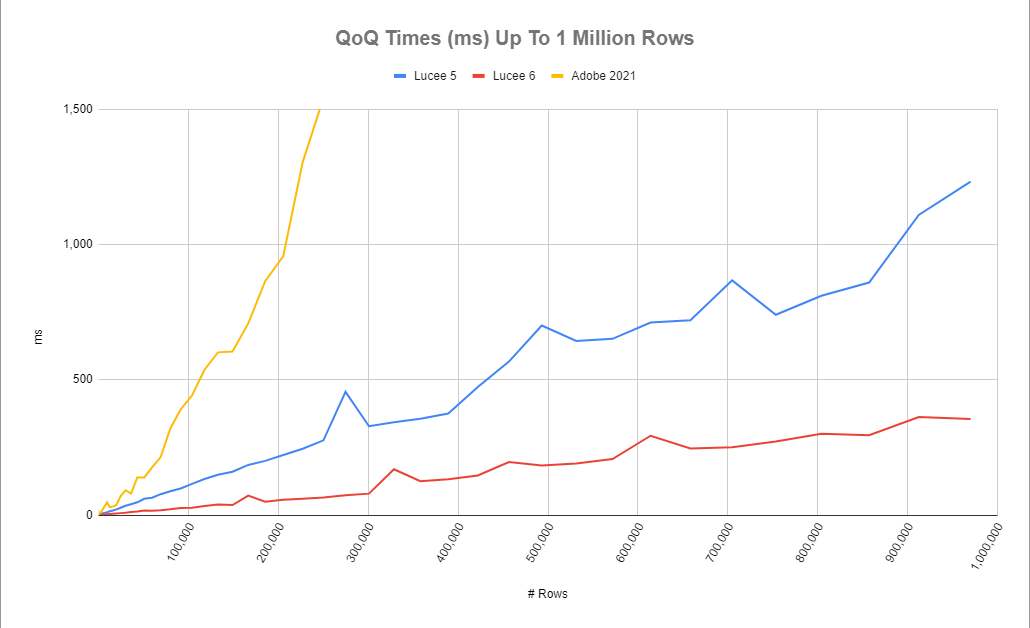
That's better. As you can see, Lucee was already quite stable selecting from large result sets, and these changes in Lucee 6 have a consistent savings which make QoQ's around 2x faster across the board.
Conclusion
- Java parallel streams are pretty cool. (See the xxxEach() functions with parallel=true for a similar CFML experience)
- I can't wait for Lucee 6 to come out (assuming my pull request gets merged!)
- QoQ is very much a performant and useful tool, no matter what some people say about it :)
- Adobe needs to step up their game on QoQ. Lucee is starting to make them wear clown shoes by showing just how good QoQ can be if some time is spent to tune it.
- I look forward to this getting some testing as Lucee 6 nears release and I'd love to see some performance numbers from anyone who relies heavily on QoQs for reporting or otherwise.
Ben Nadel
Very cool and super impressive performance graphs. At first, when I read that you were doing this with threads, I was surprised to see that it was a performance boost (since I've seen threads have a non-trivial overhead). But, then I saw that you were only using threads after a threshold, it made sense. Though, admittedly, a threshold of 50-rows feels small. But, I think that's more an indication of the QoQ overhead and less about the threads.
Anyway, awesome work!
Brad Wood
Thanks Ben! I agree with you-- I expected the threshold to be higher as well. I did extensive testing with many different complexities of queries and was surprised to see the benifit of threading consistently seemed to kick in over about 50 rows (even if it was 2ms vs 1ms) so I went with the science on it, lol. Keep in mind, creating threads in CFML is "heavier" because the entire page context has to be cloned for every thread so CF code still works. Native Java threading has no such requirement. Plus, the thread pool is re-using the same threads, not creating new ones, so the overhead really just comes down to breaking up the work amongst the pool of threads and joining them all back together at the end.
it's also worth noting, I provided an env var/system prop to control the parallelism threshold in case people wanted to play with it. It is a server-wide setting that applies to all QoQ.
Ben Nadel
Ooooh right, because you're in the Java layer. I knew that, but I don't think it was clicking for me consciously. I was about to say that it would be cool to be able to spawn threads without the Page Context ... but then, I realize that it's the Page Context that basically makes everything work in ColdFusion.